Introduction to Neural Networks and Backpropagation
Tue 30 Apr 2024 - 10 min read | 1 view(s)
The first in a mini-series of blogposts, where I explain concepts in
mathematics, statistics and machine learning as a way to get more familiar
with the concepts myself.
The Neural Network, also known as a neural net or artificial neural network,
is a model of the biological neural networks like that of brains. This model
has shown remarkable abilities in many areas of computer science such as
image classification, recommendation systems, sequence modelling and other
function approximation tasks.
In this little blog post i'll be going over the basics of neural networks as
well as a common optimization algorithm used to train them.
An introduction to Neural Networks
A neural network attempts to model biological nervous systems using many layers
of stacks of artificial neurons. The underlying model of these neurons were
first popularised by Frank Rosenblatt in 1958 in the paper "The Perceptron: A
probabilistic model for information storage and organization in the brain"
.
In the brain, neurons receive input signals through dendrites, process these
signals in the cell body, and then send an output signal through the axon to
connected neurons. Similarly, an artificial neuron in a neural network receives
input signals from other neurons, performs a calculation based on these inputs
and an activation function, and then sends an output to the next layers of
neurons.
Perceptron (single-neuron function)
The perceptron works by receiving inputs , where every represents
the -th input. These inputs have individually adjustable weights and
together with make up a linear transformation of the inputs, here a
weighted input of and , and a bias of .

This means multiplying every input with the corresponding weight , and
then summing up these weighted transformations and adding the bias. This
transformation is denoted by and makes up the core of our neuron function.
Then the data is passed through to an activation function, a non-linear
function that decides whether or not the neuron "activates". Commonly used
activation functions include ReLU, sigmoid and hyperbolic tangent, but they all do
essentially the same thing. The significance of these activations functions
will be quickly explained later.
In the original paper the activation function was a simple stepwise function:
if was greater than , otherwise .
where
is the output of the neuron
is the -th input
is the -th inputs weight
is the bias
is the number of inputs
The underlying mathematical model for a neuron uses a more standard notation,
where represents any possible activation function like ReLU.
Where is a scalar that represents the pre-activation weighted sum and
is a scalar that represents the output of the neuron after the activation.
This becomes cumbersome notation for when we need to describe larger networks
with multiple layers or multiple neurons per layer. For this reason we can make
use of vector and matrix notation to better organise our data.
Now we can instead represent both and as column-vectors.
Here the whole notation for the weighted sum can be simplified to the
dot-product of the two vectors, where we then add the bias term and it is
passed to the activation function.
So to summarise, the underlying function of neurons takes an input vector 𝑥
and produces a scalar, which is the dot product of 𝑥 and the weights 𝑤 or
the weighted sum of inputs. A bias is added to this, and a nonlinear
activation function is applied.
The activation function is important, as the element of a non-linear
activation allows a more complex network to model non-linear relationships
in data. Without these activations, the network would simply combine linear
functions, resulting in an overall linear transformation of the input in the
neural network, simplified here:
Multiple neurons and the MLP
In a neural network with multiple layers of neurons (multi-layer
perceptron), the structure is more complex than a single layer with a single
neuron. The term "deep learning" originates from these more complex
networks, which consist of multiple layers of neurons.
In a single-layer network with multiple neurons, the output for each
individual neuron can be calculated by considering all the previous inputs.
This is because the network is densely connected, also known as a
fully-connected network or fully-dense network.
In this context, the individually calculated scalars can be represented as a
column-vector of the activations in a layer , where denotes the
index of the layer.
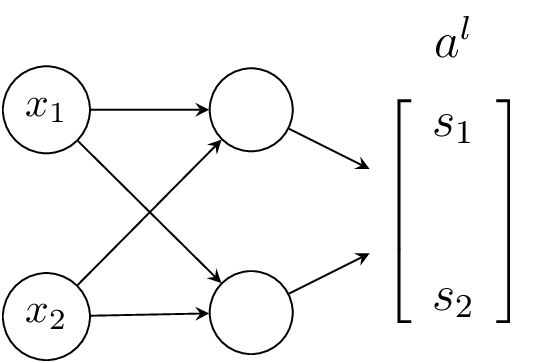
This representation makes it easier to work with multiple layers as it
allows us to visualise the interconnection of multiple neurons across the
layers.
The weights in the fully-dense layer can now be represented as a matrix
in a layer with neurons and inputs, where is the
layer, is the index of neuron the connection is going to and is the
index of the neuron the connection is coming from.
and the bias can now also be represented as a column-vector of the
pre-activation bias terms for every neuron in a layer .
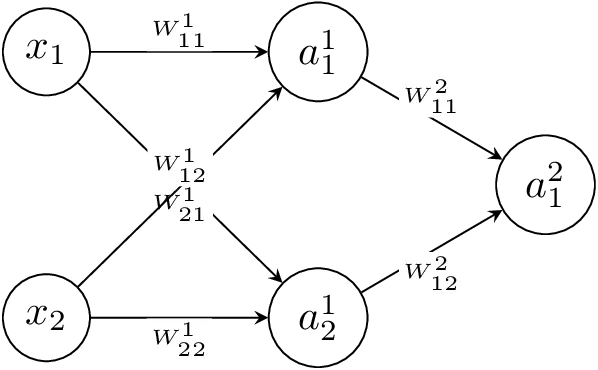
Now the activation for a whole layer based on the activations of the previous layer (inputs) can be represented as
or more verbously
and so the activation of the entire network in the figure above can be represented as
where are the inputs to the network and is the final output.
This can also be written more generally as
where is the activation in layer (the amount of layers in the network).
This entire process is called feed-forward and refers to the forward
propagation of the inputs through these data transformations until you get
an output. Optimising or training these networks is harder but a nice
algorithm called Backpropagation makes it easier to grasp.
Backpropagation and optimization (training)
Neural networks learn by "tuning" these weights based on an error
calculation of the network's output with respect to the input. One of the
most commonly used methods to achieve this is the backpropagation algorithm.
Backpropagation utilises the chain rule from differential calculus to
compute the gradient of the loss function, also known as an objective
function, with respect to the weights in the neural network. Backpropagation
evaluates how a small change in a weight or bias affects the overall error,
and then adjusts these parameters in the direction of minimising the error.
Loss calculation
Typically, a loss function is used to quantify how much the network's
predictions deviate from the actual values in the training data. A common
choice for the loss function in regression is Mean Squared Error (MSE).
In order to calculate the gradient, the partial derivative of the loss
function with respect to the parameters in the network, we use
backpropagation and the chain rule.
Let the loss function be and let represent the loss in the
last layer . Here the loss is defined as
as we want to understand how the
pre-activations in a layer () affect .
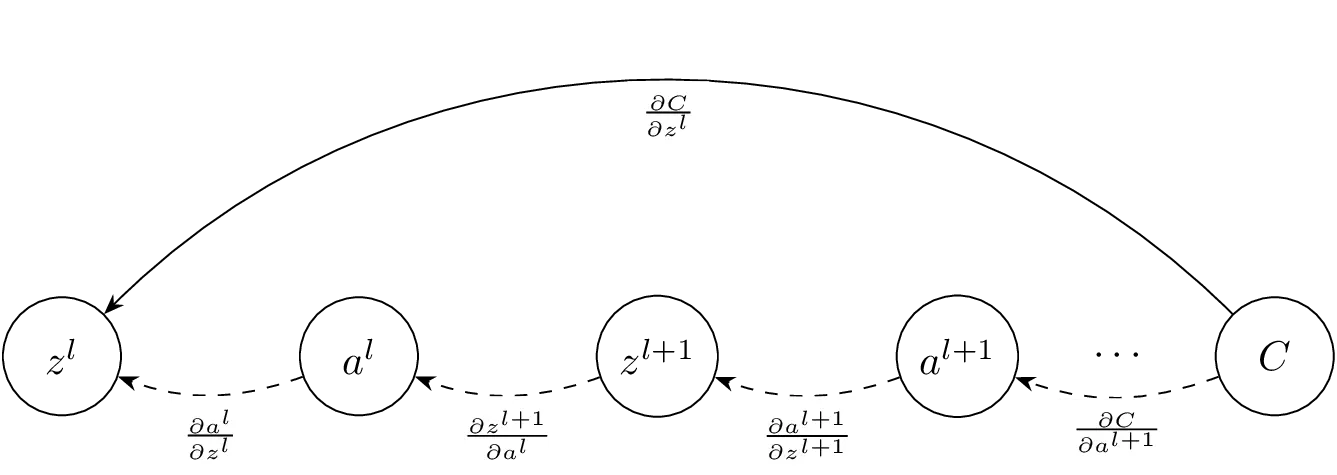
We start by using the chain rule, , in order
to calculate the loss in the last layer .
In order to calculate the loss in any layer () we start from
the loss function and calculate
backwards from to the layer .
We can use the chain rule to compute the loss in the last layer
as well as step-by-step backwards from the last layer to layer :
Deriving from this method we can more neatly represent the loss in a layer
by looking at the next layer and represent
as
whose components are
which is the partial derivative of
the activation function applied to , .
which is the partial
derivative of the pre-activation in the next layer with respect to . Here, the partial derivative of
with respect to is
(transposed), as the partial derivative of a matrix product with
respect to is . This also makes intuitive sense
since we transpose the matrix to propagate the loss backwards through
the network.
which is the partial derivative
of the loss function with respect to the pre-activations in the
next layer, which can also be rewritten as .
Now, we can compute the loss in any layer :
Substituting the previously found components, we get:
Finally, the gradients are computed, which are the changes in the loss function
with respect to the parameters and :
Now that we know how each parameter in our neural net influences the loss, we
just need to figure out how to optimize our network to minimise the loss.
Luckily, there is a simple and effective way of doing that as we've already
done the hard part.
Gradient descent and optimization
The gradients we calculated are used in optimization algorithms to adjust
randomly initialised parameters, the weights and biases, in a neural network
with the aim of minimising the loss function.
Stochastic gradient descent (SGD) is a variant of gradient descent
used in machine learning. SGD updates the weights iteratively for each
training instance based on the gradient of the error function, which is
more efficient for large datasets.
where is the parameters, is the learning rate that controls
the size of the update, and
() is the gradient of
the error function with respect to the parameters .
In this way, a network can iteratively learn to minimise the loss for an
arbitrary underlying function.